python面试 自我介绍目录
python面试 自我介绍
面试官您好,我叫张三,我是一名有着两年工作经验的Python开发工程师。我擅长使用Python进行数据分析、机器学习和Web开发。
我对Python的语法和库有深入的了解,并且在实际项目中,能够熟练地运用Python进行数据清洗、数据可视化、机器学习模型构建等任务。此外,我也具备一定的Web开发经验,能够使用Flask或Django等框架搭建Web应用。
在工作中,我注重代码的可读性和可维护性,并且善于与团队成员进行有效的沟通和协作。我曾参与过多个大型项目的开发,并在项目中发挥了积极的作用。
总之,我相信我的技能和经验能够为贵公司带来价值。我期待能够成为贵公司的一员,与大家一起共同成长。
Python后端开发工程师面试
第一步:自我介绍
第二步:公司介绍
第三步:技术基础
第四步:项目介绍
第五步:待遇
自我介绍,简单直接,姓名,籍贯,大学,工作经历
示例如下:
你好,面试官,我叫XX,来自XX,本科毕业于XX,主修XX专业,有X年工作经验,在上一家公司担任python后端开发工程师的职位。
公司名称是XX、公司主要做外包软件、都有软件定制/商城定制、前端2个后端2个运维1个
主要是根据你简历中填写的技术,根据我的简历中所写的,总结几点如下:
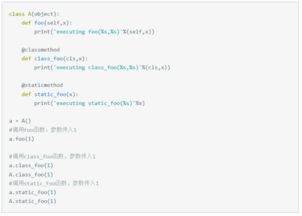
字典的查询流程:
不可变对象可哈希, str , fronzenset , tuple ,自己实现的类,要重载 __hash__ 方法。
dict内存花销大,但是查询速度快,自定义的对象或者python内部的对象都是dict包装的。
dict的存储顺序和元素添加顺序有关,添加顺序可能改变已有数据的顺序。
集合:是一个可以存放任意数据类型的可变无序的映射集合。
set和dict类似,set的核心也是散列表,但是表元只包含值的引用。
由于散列表的特性,set的元素不能重复,且无序。
内部由哈希实现,查找的时间复杂度为O(1),所以性能很高,实现了魔法函数 __contains__ 可以使用in来查找。
set的去重是通过两个函数 __hash__ 和 __eq__ 实现的。
(1)浅拷贝
定义:浅拷贝只是对另外一个变量的内存地址的拷贝,这两个变量指向同一个内存地址的变量值。
浅拷贝的特点:
(2)深拷贝:
定义:一个变量对另外一个变量的值拷贝。
深拷贝的特点:
Python GC主要使用引用计数(reference counting)来跟踪和回收垃圾。
在引用计数的基础上,通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用问题,通过“分代回收”(generation collectio n)以空间换时间的方法提高垃圾回收效率。
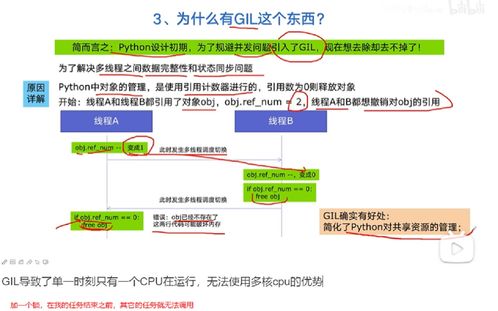
GIL全称 Global Interpreter Lock ,中文解释为全局解释器锁。
它并不是Python的特性,而是在实现python的主流Cpython解释器时所引入的一个概念,GIL本质上就是一把互斥锁,将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,从而保证数据的安全性。
GIL保护的是解释器级别的数据,但是用户自己的数据需要自己加锁处理。
既然有了GIL的存在,一个进程中同一时刻只有一个线程能够被执行,无法利用cpu的多核机制,导致多线程用于I/O密集型,多进程用于计算密集型,如金融分析等。
死锁:两个或两个以上的进程或者线程在执行过程中,因为争夺资源而造成的互相等待现象,若无外力的作用,都将一直处于阻塞状态,这些互相等待的进程或者线程就被称为死锁。
解决方法,使用递归锁(RLock)
这个RLock内部有一个Lock和一个counter变量,counter记录着acquire的次数,从而使得资源可以被多次require。
直到一个线程所有的acquire都被release,其他的线程才能获得资源。
上面的例子如果使用RLock代替Lock,则不会发生死锁
可以直接认为是linux,毕竟搞后端的多数是和linux打交道。
那么如何避免粘包问题呢? 归根结底就是一句话, 明确两个包之间的边界.
UDP不存在粘包问题,是由于UDP发送的时候,没有经过Negal算法优化,不会将多个小包合并一次发送出去。
另外,在UDP协议的接收端,采用了链式结构来记录每一个到达的UDP包,这样接收端应用程序一次recv只能从socket接收缓冲区中读出一个数据包。
也就是说,发送端send了几次,接收端必须recv几次(无论recv时指定了多大的缓冲区)。
存储可能包含rdbms,nosql以及缓存等,我以mysql,redis举例**
程序员面试应该怎么怎样自我介绍

一段短短的自我介绍,其实是为了揭开更深入的面谈而设计的。
一、两分钟的自我介绍,犹如商品广告,在有限的时间内,针对客户的需要,将自己最美好的一面,毫无保留地表现出来,不但要令对方留下深刻的印像,还要即时引发起购买欲。
1.自我认识
想一矢中的,首先必须认清自我,一定要弄清以下三个问题。
你现在是干什么的?你将来要干什么?你过去是干什么的?
2、投其所好
清楚自己的强项后,便可以开始准备自我介绍的内容:包括工作模式、优点、技能,突出成就、专业知识、学术背景等
3、铺排次序
内容的次序亦极重要,是否能抓住听众的注意力,全在于事件的编排方式。
所以排在头位的,应是你最想他记得的事情。
而这些事情,一般都是你最得意之作。
与此同时,可呈上一些有关的作品或纪录增加印像分。
求职个人自我介绍是面试实战非常关键的一步,因为众所周知的“前因效应”的影响,你这2-3分钟见面前的自我介绍将在很大程度上决定你在各位考官心里的形象。
这份介绍将是你所有工作成绩与为人处世的总结,也是你接下来面试的基调,考官将基于你的材料与介绍进行提问。
个人单独面试基本上都是从开场问候开始,开场问候很重要,它有可能决定整个面试 的基调。
开场问候是给面试考官的第一印象,从言谈举止到穿着打扮将直接影响到你被录取的机会。
进门应该面带微笑,但不要谄媚。
话不要多,称呼一声“老师好”就足够,声音要足够洪亮,底气要足,语速自然,总之彬彬有礼而大方得体,不要过分殷勤,也不要拘谨或过分谦让。
接下来就是自我介绍;面试中一般都会要求考生先做简单的自我介绍,自我介绍的时间一般为2-3分钟左右。
自我介绍是很好的表现机会,应把握以下几个要点:首先,要突出个人的优点和特长,并要有相当的可信度。
特别是具有实际管理经验的要突出自己在管理方面的优势,最好是通过自己做过什么项目这样的方式来验证一下;其次,要展示个性,使个人形象鲜明,可以适当引用别人的言论,如老师、朋友等的评论来支持自己的描述;第三,不可夸张,坚持以事实说话,少用虚词、感叹词之类;最后,要符合常规,介绍的内容和层次应合理、有序地展开。
最后,要符合逻辑,介绍时应层次分明、重点突出,使自己的优势很自然地逐步显露,不要一上来就急于罗列自己的优点。
自我介绍的格式
自我介绍的格式是:基本信息、教育背景和工作经历、个人特长和兴趣爱好、性格特点和价值观、未来规划和期望。
1、基本信息。
基本信息包括姓名、年龄、籍贯、职业等。
例如:大家好,我叫张三,今年25岁,来自北京,是一名软件工程师。
2、教育背景和工作经历。
例如:我毕业于清华大学计算机科学与技术专业,曾在一家知名互联网公司担任后端开发工程师,负责过多个项目的设计和开发工作。
3、个人特长和兴趣爱好。
例如:我热爱编程,擅长使用Python和Java进行软件开发。
业余时间喜欢阅读科技类书籍和参加技术沙龙活动。
4、性格特点和价值观。
例如:我是一个乐观积极的人,善于与人沟通和合作。
我认为诚信、勤奋和创新是实现个人价值和社会价值的关键。
5、未来规划和期望。
例如:我希望在未来几年内能够在技术领域取得更高的成就,为公司的发展做出更大的贡献。
同时,我也期待与更多志同道合的朋友共同成长和进步。
自我介绍的作用:
1、了解个人背景:自我介绍可以介绍个人基本信息,包括姓名、年龄、职业、家乡、人生经历等,让面试官迅速了解你的背景信息。
2、展现个人素质:通过自我介绍,可以展现你的个性、特点、技能和潜力,让面试官了解到你的优势及擅长领域,也可以通过展示个人素质来赢得面试官的信任和支持。
3、自我定位:自我介绍可以凸显个人的职业规划目标和业务能力,面试官会通过面试者的自我定位和职业规划,了解面试者的职业发展方向和目标,间接推测出其未来的工作表现。
4、突出优势:自我介绍中更透露的是面试者本人的特点和技能,突出自己最擅长的领域和重点实践经历,展现自己的优势,从而赢得面试者的关注和认可。