。
。
。
。
。
5. 使用命令行工具进行分析:Linux系统提供了大量的命令行工具,例如ps、top、netstat等,可以对系统进行实时监控和分析,帮助排查故障。
。
Linux启动故障处理
【摘要】
当Linux系统出现故障无法正常启动系统时,Linux准备了单用户模式、救援模式等方式可以让我们有效的处理这类问题。
本文简单分享一个利用救援模式解决Redhat系统无法启动的案例。
【正文】
一、问题背景
1)问题描述
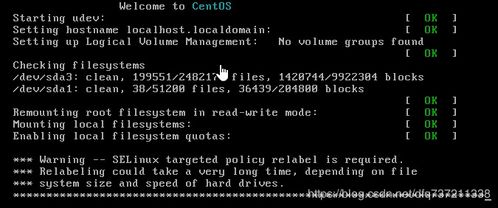
一台部署了RHEL 7.2的物理服务器,突发死机故障,在尝试重启时,发现服务器无法正常进入操作系统,直接进入emergency mode。
本文主要分享操作系统启动异常的问题排查过程。
(服务器死机据后续日志分析,确定为内核的bug所致,本文不进行累述)
2) 故障现象
系统启动后,提示无法找到/dev/mapper/rhel-root,并直接进入emergency mode。
二、排查思路
1)收集系统启动异常的相关提示信息,获取到问题关键点:
Warning:/dev/rhel/root does not exist
初步定为配置文件问题或者逻辑卷root本身问题;
2)尝试在应急模式下检查逻辑卷状态,发现当前情况并不稳定,常用命令无法使用、显示多为乱码;
3)尝试进入单用户模式,发现情况和应急模式一样;
Redhat 7.2进入单用户模式:
1、开机启动至内核选择界面,选择第一项,按e进行编辑
2、定位到linux16这一行,找到ro,修改其为rw init=/sysroot/bin/sh
3、按ctrl+X启动至单用户模式
4)利用系统安装光盘,进入Linux救援模式,进行排查。
Redhat 7.2救援模式启动方法:
1、把光盘加入光驱,然后启动,以光盘进行引导,选择救援模式(中间具体的步骤不再细说)
2、文件系统挂载到/mnt/sysimage目录下,这时切换到此目录下使用chroot /mnt/sysimage这条命令即可
5)在救援模式下,首先查看服务器lv的情况,发现所有lv
status均为未激活状态。
查看lv
#Lvdisplay
修改lv
#vgchange -a y /dev/docker/root
6)在尝试修改root的lv status时,发现root所在的vg名和启动时所指定的vg名不一致,基本确定问题点;
7)修复
l 编辑文件/etc/default/grub
l 修改此文件中GRUB_CMDLINE_LINUX一行中rd.lvm.lv为合适的值
l 再执行以下命令重做grub :
nUEFI: grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
n 非UEFI:grub2-mkconfig -o /boot/grub2/grub.cfg
l 查看文件grub.cfg中是否修改为rd.lvm.lv=rhel/root
l 修改/etc/grub2.cfg中root=后接的lv路径改为实际的路径。
8)系统启动后,通过history日志,确定为该系统业务部署时,使用了vgrename命令修改了vg名。
三、总结
对于Linux的问题处理,需要对Linux的运行原理有所理解,这此前提下才能根据有限的提示信息判断问题方向、确定排查范围、找到解决方法。
同时,提醒各位初学linux的同事么,在进行linux的一些操作时,需要充分考虑这些操作可能造成的影响,避免类似上述的问题发生。
转自 嘉为教育-rhce认证_rhce培训_linux培训_linux认证_linux考证
linux故障排除的常用方式有哪些
1、使用急救盘组进行维护
2、2.文件系统被破坏时的处理方法
当文件系统被破坏时,如果使用的是ext2fs类型的文件系统,就可从软盘运行e2fsck命令来修正文件系统中被损坏的数据。
3.恢复丢失的文件
如果不小心删除了重要的文件,还可以将相应的文件从急救盘复制到硬盘上。
例如,删除了文件/bin/login,此时系统无法正常运行到登录界面,可以用急救盘组启动系统,将硬盘文件系统安装到/mnt目录下,然后使用下述命令:
#cp -a /bin/login /mnt/bin
“-a”选项用于告诉cp在拷贝时保持文件的访问权限。
当然如果被删除的基本文件不在“急救盘组”中,也就不能用这种方法了。
如果以前做过系统备份的话,那么就只有用以前的备份来恢复了。
4.函数库破坏时的处理方法
最简单的解决办法是用急救盘组启动系统,在/mnt目录中安装硬盘文件系统,然后修复/mnt/lib目录下的库。
5.无法用root账号登录系统
由于系统管理员的疏忽,或者由于系统受到黑客的入侵,系统管理员可能无法用root帐号登录系统。
对于第1种情况,可能是系统管理员忘记了root密码,用急救盘组就可以解决问题。
对于第2种情况,由于很可能是密码被黑客修改了,因此系统管理员无法进入系统,也就是说,Linux系统完全失去了控制,因此应尽快重新获得系统的控制权。
在取得 root权限后,还应检查系统被破坏的情况,以防被黑客再次入侵。
需要做的最主要的工作就是重新设置root的密码,获得Linux操作系统的控制权。
首先用急救盘组启动系统,然后将硬盘的文件系统安装到/mnt目录下,编辑/mnt/etc/passwd文件,将其对应于root账户的一行加密口令域置空,如下所示:
root::0:0:root:/root:bin/bash
注:如果系统使用 shadow工具,就需要对文件/etc/shadow进行上述的操作,使root登录系统不需要口令。
这样,root账户就没有口令了。
当重新从硬盘启动Linux系统时,就可以用root账户登录(系统不会要求输入密码)。
进入系统后,再用命令passwd设置新的口令。
6.系统不能启动
一般来说,如果系统管理员不能正常进入系统,就需要考虑使用急救盘组进入急救模式排除系统的故障。
但在没有制作急救盘组的情况下,Linux系统不能启动,该怎么办呢?
在个人计算机使用 Linux系统时,通常都是Linux和MS Windows 9X或MS Windows NT并存的。
由于重新安装其他的操作系统,经常会导致原有的Linux不能启动。
这主要是因为,这些操作系统默认为计算机中没有其他的操作系统,因而改写了硬盘的主引导记录(MBR),覆盖掉了Linux的LILO系统引导程序。
如果有急救盘组,那么很简单,用第一张启动盘启动硬盘的Linux系统,重新运行LILO命令,就可以将LILO系统引导程序写回硬盘的主引导记录,再次开机即可。
如果没有系统启动盘,如果知道Linux在硬盘上的确切安装分区,且有loadlin程序,就可以重新返回Linux。
loadlin是DOS下的程序,运行它可以从DOS下直接启动Linux,快速进入Linux环境。
在 Red Hat Linux 6.0光盘的 dosutil目录下就有这个程序。
除此之外,还需要一个 Linux启动内核的映像文件vmlinuz,在 Red Hat linux 6.0光盘的 images目录下就有这个文件。
例如,在Windows 98系统下面,进入DOS的单用户模式,然后运行下述的loadlin命令,即可重新进入Linux系统:
loadlin vmlinuz root=/dev/hda8
/dev/hda8是Linux的root文件系统所在的硬盘分区位置。
命令执行后,就开始引导Linux系统。
用root身份登录后,运行LILO命令,则重新将LILO装入MBR,回到以前多操作系统并存使用的状态。
7.处理不正常关机引起的故障
如果Linux不正常关机,有可能导致不能进入Linux的KDE环境而只能处于控制台环境下,而且不断地有大片大片的英文字符向上翻滚。
以root身份login后,键入startx命令,出现“x server不能连接”的错误提示。
这时可以在控制台下,键入setup,出现系统设置菜单,选择其中的“X窗口设置”,然后依照提示正确设置显示器的类型、刷新频率、显存大小、分辨率等。
如果一切无误,系统会自动启动X Windows系统,一切便OK了!需要注意的一点是:在用setup进行设置时,可能还会有大片大片的英文字符向上翻滚,请不要惊慌,看清屏幕,继续使用TAB键或方向键,马上便会“柳暗花明”的。
Linux系统CPU内存使用率过高的问题排查

服务器出现由内存问题引发的故障,例如系统内部服务响应速度变慢、服务器登录不上、系统触发 OOM(Out Of Memory)等。
通常情况下当实例内存使用率持续高于90%时,可判断为实例内存使用率过高。
CPU/内存使用率过高的问题原因可能由硬件因素、系统进程、业务进程或者木马病毒等因素导致。
笔者以前写过一篇文章- Linux 下的 60 秒分析的检查清单 ,适用于 任何性能问题 的分析工作,这一篇文章是关于CPU/内存使用率的具体的排查思路总结。
执行top命令后按 M ,根据驻留内存大小进行排序,查看 “RES” 及 “SHR” 列是否有进程占用内存过高。
按 P,以 CPU 占用率大小的顺序排列进程列表,查看是否有进程占用cpu过高。
如果有异常进程占用了大量 CPU 或内存资源,记录需要终止的进程 PID,输入k,再输入需要终止进程的 PID ,按Enter。
另外说明一下,top 运行中可以通过 top 的内部命令对进程的显示方式进行控制,最常用的是M和P。
CPU 空闲但高负载情况,Load average CPU 负载的评估,其值越高,说明其任务队列越长,处于等待执行的任务越多。
执行ps -axjf命令,查看进程状态,并检查是否存在 D 状态进程。
D 状态指不可中断的睡眠状态,该状态进程无法被杀死,也无法自行退出。
若出现较多 D 状态进程,可通过恢复该进程依赖资源或重启系统进行解决。
Linux 系统通过分页机制管理内存的同时,将磁盘的一部分划出来作为。
而 kswapd0 Linux 系统虚拟内存管理中负责换页的进程。
当系统内存不足时,kswapd0 会频繁的进行换页操作。
换页操作非常消耗 CPU 资源,导致该进程持续占用高 CPU 资源。
执行top命令,找到 kswapd0 进程。
观察 kswapd0 进程状态,若持续处于非睡眠状态,且运行时间较长并持续占用较高 CPU 资源,执行vmstat,free,ps等指令,查询系统内进程的内存占用情况,重启系统或终止不需要且安全的进程。
如果 si,so 的值也比较高,则表示系统存在频繁的换页操作,当前系统的已经不能满足您的需要。
si 表示每秒从交换区写入内存的大小(单位:kb/s) , so 每秒从内存写到交换区的大小。
执行cat/proc/meminfo |grep-i shmem命令查看。
buddy可以以页为单位获取连续的物理内存了,即4K为单位。
slab负责需要频繁的获取/释放并不大的连续物理内存,比如几十字节。
执行cat /proc/meminfo | grep -i SUnreclaim命令查看slab 内存。
标准的 4KB 大小的页面外,内存大页管理内存中的巨大的页面,处理较少的页面映射表,从而减少访问/维护它们的开销。
执行cat /proc/meminfo | grep -iE "HugePages_Total|Hugepagesize" 查看内存大页。
内存使用率计算:
(Total - available)100% / Total
(Total - Free - Buffers - Cached - SReclaimable + Shmem)* 100% / Total
cat /proc/meminfo查看信息含义: