linux中grep是什么意思,Linux使用之grep,shell脚本(一)
linux中grep是什么意思目录
linux中grep是什么意思
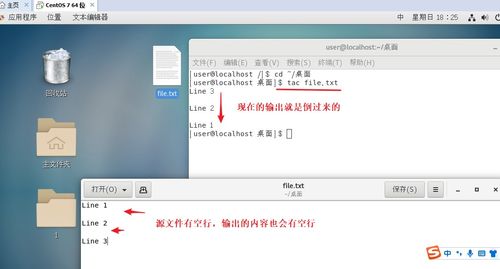
在Linux系统中,grep是一个强大的文本搜索工具,它使用正则表达式来搜索文本,并把匹配的行打印出来。其全称为Global Regular Expression Print,即全局正则表达式版本。
grep的工作方式是在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到屏幕,不影响原文件内容。
grep家族包括grep、egrep和fgrep。其中,egrep扩展了grep,支持更多的正则表达式元字符;fgrep将所有的字符当作字面值,即正则表达式元字符不再是特殊字符。
以上内容仅供参考,建议查阅Linux相关书籍或咨询专业人士获取更多信息。
Linux使用之grep,shell脚本(一)
在使用Linux的过程中,场景有时候便会涉及到查找文本文件的内容,假如现在我们想要在一个三百多行的文本中找到特定的语句,或者在这其中查找是否含有特定的字段应该怎么办呢?
这里便出现了专门的文本处理工具——grep,grep是Linux中常用的文本处理工具之一。
grep的全称为“ Global search Regular Expression and Print out the line”。
全称中的“Glibal search”意思为全局搜索的意思。
全称中的“Regular Expression”意思为正则表达式。
所以从全称中就可以理解为gerp是一个可以利用正则表达式的全局搜索工具。
grep会按照正则表达式的匹配原则在文本文件中按照逐行匹配处理的方法来处理文本并输出。
来看看grep的用法。
来看看案例。
案例1.统计出/etc/passwd文件中其默认shell为非/sbin/nologin的用户个数,并将用户都显示出来
上面的案例开始匹配了/sbin/nologin关键词,但是案例中只需要除了它之外的shell,所以讲它使用-v选项排除开就可以了。
案例2.查出用户UID最大值的用户名、UID及shell类型
案例3.统计当前连接本机的每个远程主机IP的连接数,并按从大到小排序
上面的案例中ss -nt 查看连接情况,然后将EATAB状态的过滤出来,在进行处理,最后提取出结果并完成排序。
案例4:编写脚本disk.sh,显示当前硬盘分区中空间利用率最大的值
案例5.编写脚本 systeminfo.sh,显示当前主机系统信息,包括:主机名,IPv4地址,操作系统版本,内核版本,CPU型号,内存大小,硬盘大小
linux命令里,grep * 是什么意思?

任意一个字节 . 与重复字节 *
这两个符号在正则表达式的意义如下:
. (小数点):代表『一定有一个任意字节』的意思;
* (星号):代表『重复前一个字符, 0 到无穷多次』的意思,为组合形态
假设我需要找出 g??d 的字串,亦即共有四个字节, 起头是 g 而结束是 d ,我可以这样做:
1:"Open Source" is a good mechanism to develop programs.
9:Oh! The soup taste good.
16:The world <Happy> is the same with "glad".
因为强调 g 与 d 之间一定要存在两个字节,因此,第 13 行的 god 与第 14 行的 gd 就不会被列出来啦!
如果我想要列出有 oo, ooo, oooo 等等的数据, 也就是说,至少要有两个(含) o 以上,该如何是好?
因为 * 代表的是『重复 0 个或多个前面的 RE 字符』的意义, 因此,『o*』代表的是:『拥有空字节或一个 o 以上的字节』,因此,『 grep -n 'o*' regular_express.txt 』将会把所有的数据都列印出来终端上!
当我们需要『至少两个 o 以上的字串』时,就需要 ooo* ,亦即是:
1:"Open Source" is a good mechanism to develop programs.
2:apple is my favorite food.
3:Football game is not use feet only.
9:Oh! The soup taste good.
18:google is the best tools for search keyword.
19:goooooogle yes!
如果我想要字串开头与结尾都是 g,但是两个 g 之间仅能存在至少一个 o ,亦即是 gog, goog, gooog.... 等等,那该如何?
18:google is the best tools for search keyword.
19:goooooogle yes!
如果我想要找出 g 开头与 g 结尾的行,当中的字符可有可无
1:"Open Source" is a good mechanism to develop programs.
14:The gd software is a library for drafting programs.
18:google is the best tools for search keyword.
19:goooooogle yes!
20:go! go! Let's go.
因为是代表 g 开头与 g 结尾,中间任意字节均可接受,所以,第 1, 14, 20 行是可接受的喔! 这个 .* 的 RE 表示任意字符是很常见的.
linux三剑客的基本使用——grep、sed、awk
grep、sed、awk是linux功能非常强大的三个命令,grep是查找过滤文本,sed是对文本进行编辑替换,awk是对文本进行分析报告。
最简单的理解就是找什么东西用grep,想修改什么内容用sed,想格式化内容用awk。
创建一个文件名为grep_text.txt的文件,并放入内容:
SillyMadman is both a madman and a fool.
Everyone agrees with this sentence.
我要查找在grep_text.txt文件里有Silly的行
命令是: grep Silly grep_text.txt
会返回内容:SillyMadman is both a madman and a fool.
也可以带以下参数,这些我认为可能容易用到的参数,其它的参数需要另行查找
文档,比如可以使用正则进行匹配。
内容相关的
-B, --before context=NUM显示所在行之前的行数
-A, --after context=NUM显示所在行之后的行数
-C, --context=NUM打印输出上下文的行数
过滤内容相关的参数:
-i, --忽略大小写区分
-w,--匹配查找的整个单词
-x,--匹配查找的整行文本
-v, --过滤掉匹配的内容
输出内容相关的参数
-n, --行号打印带有输出行的行号
比如,我要查找在grep_text.txt文件里不区分大小写查找sillymadman,并显示行号和匹配文本的下一行,那么我可以用以下命令查找
grep sillymadman grep_text.txt -i -n -A1
内容返回为
1:SillyMadman is both a madman and a fool.
2-Everyone agrees with this sentence.
总体而言grep的使用方式就是
grep [参数...](查找的内容) (文件名)
grep也经常搭配管道符号"|"使用,比如我要查询某程序的进程,并去掉查找进程本身,那么命令为
ps -ef | grep program_name | grep -v grep
再创建一个文件名为sed_text.txt的文件,并放入内容:
SillyMadman is both a madman and a fool.
Everyone agrees with this sentence.
我想要在第一行下面添加一句:woshishazi
命令是:sed 1awoshishazi sed_text.txt
返回内容为:
SillyMadman is both a madman and a fool.
woshishazi
Everyone agrees with this sentence.
但是以上这个命令不会修改原文件,如果需要,需要加上-i
sed -i 1awoshishazi sed_text.txt
上面a是代表append,从指定行后面新的一行添加数据,还有其他操作
操作有以下这些
a :从下面一行新增
i :从上面一行插入,
d :删除
c :整行替换
p :打印
s :对指定内容进行替换
下面稍微举下例:
a: sed 1awoshishazi sed_text.txt 从第一行后面添加
i: sed 1iwoshishazi sed_text.txt 从第一行前面插入
d: sed 1d sed_text.txt 删除第一行
c: sed 1cwoshishazi sed_text.txt 替换第一行内容为woshishazi
p: sed -n 1p sed_text.txt 打印第一行,一般搭配-n使用,其他内容就不会再展示
s:这个相对复杂一点需要详细说明一下
sed的参数为 [行]s/要被替换的内容/新的内容/g
行是一个可选项,可以选择具体的行进行替换
g代表替换所有匹配到的内容,也可以改为数字,表示第几次匹配到时进行替换
sed sSillyMadmanshafengzig sed_text.txt ,将所有SillyMadman替换为shafengzi
输出结果为:
shafengzi is both a madman and a fool.
Everyone agrees with this sentence.
最后再创建一个文件名为awk_text.txt的文件,并放入内容:
1 a
2 b
3 c
4 d
5 f
以空白符作为这个文本相当于每一行有两个字段。
那么打印第一个字段时 awk {print 0的话,则代表打印所有字段
awk默认以空白符作为分隔符,也可以指定分割符通过-F
awk -F: {print $1} awk_text.txt,以“:”作为作为分隔符
那么返回内容就为
1 a
2 b
3 c
4 d
5 f
相当于只有一列或者说一个字段
然后还可以对前面加上一个正则对行进行匹配内容
awk /a/{print 2 ~ /a/){print $1} awk_text.txt
返回内容为
1
(随机推荐阅读本站500篇优秀文章点击前往:500篇优秀随机文章)