1. 了解爬虫的基本概念
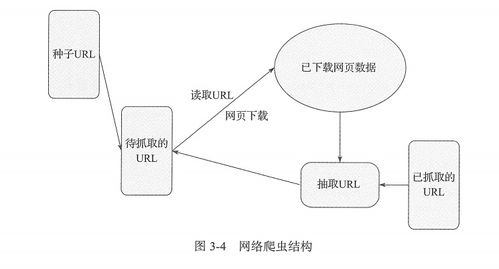
需要了解什么是爬虫。爬虫是一种自动化程序,能够模拟人类在网页上浏览和获取数据的方式,从而将网页上的数据抓取下来。在 Python 中,爬虫通常使用 Requests 和 BeautifulSoup 这两个库来实现。
2. 安装 Requests 和 BeautifulSoup 库
在开始编写 Python 爬虫之前,需要先安装 Requests 和 BeautifulSoup 库。可以使用以下命令在终端中安装这两个库:
```shell
pip install requests beautifulsoup4
```
3. 了解 HTML 结构
在进行爬虫编写之前,需要了解 HTML 的基本结构。可以通过浏览器开发者工具来查看网页的 HTML 结构,从而了解如何定位和选择网页上的元素。
4. 编写简单的爬虫程序
```python
import requests
from bs4 import BeautifulSoup
response = requests.get(url) # 发送 GET 请求
soup = BeautifulSoup(response.text, 'html.parser') # 使用 BeautifulSoup 解析 HTML
titles = soup.find_all('h1') # 选择所有的
标签元素
links = soup.find_all('a') # 选择所有的 标签元素
for title in titles:
print(title.text) # 打印文本
for link in links:
```
在这个例子中,我们首先使用 Requests 库发送 GET 请求,获取目标网页的内容。然后使用 BeautifulSoup 库将 HTML 解析成一个 BeautifulSoup 对象。接着,我们使用 find_all() 方法来选择所有的