一般来说,Python爬虫的爬取步骤可以分为以下几步:
1. 确定目标网站和数据:首先需要确定要爬取的目标网站和所需的数据。这些数据可以是网页内容、特定信息、图片、视频等。
2. 分析网页结构和数据:在确定目标数据后,需要分析网页的结构和数据。可以使用浏览器开发者工具或其他工具来查看网页的HTML结构和API接口。
3. 安装爬虫框架和库:Python有许多优秀的爬虫框架和库,如Scrapy、BeautifulSoup、Requests等。需要安装这些库和框架,以便在爬取过程中使用。
4. 编写爬虫代码:根据目标网站的结构和数据,编写相应的爬虫代码。这些代码可以通过模拟浏览器行为或直接调用网站API来获取所需数据。
5. 运行爬虫程序:在编写完爬虫代码后,可以运行程序来爬取所需的数据。如果遇到反爬虫措施,如IP限制或验证码等,需要采取相应的应对措施。
6. 数据清洗和处理:爬取到的数据通常需要进行清洗和处理,以去除无效或无关的数据,提取所需的信息。
7. 数据存储和分析:可以将爬取到的数据存储到数据库或文件中,并进行进一步的分析和处理,以满足具体需求。
使用Pyho爬虫进行网页爬取的步骤
一、引言
随着互联网的普及,网络数据量越来越大,信息交流越来越频繁。因此,爬虫技术在网络数据获取、信息抽取、数据分析等方面具有广泛的应用。Pyho作为一种流行的编程语言,具有易学易用、功能强大的特点,是开发爬虫程序的首选语言之一。本文将介绍使用Pyho爬虫进行网页爬取的步骤。
二、步骤
1. 确定目标网站和数据需求
在开始编写爬虫程序之前,需要明确要爬取的目标网站和所需的数据。根据目标网站的结构和数据格式,可以制定相应的爬取策略。同时,需要了解目标网站的爬取限制和反爬虫机制,避免被封禁或触犯法律。
2. 安装Pyho环境和相关库
在编写Pyho爬虫程序之前,需要安装Pyho环境和相关库,如requess、BeauifulSoup、Scrapy等。这些库可以用于发送HTTP请求、解析HTML页面、存储数据等操作。
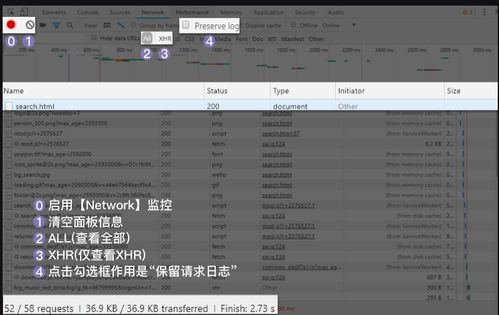
3. 分析网页结构和数据抽取规则
在确定目标网站和数据需求之后,需要对目标网站的网页结构和数据抽取规则进行分析。可以通过浏览器开发者工具或网络爬虫工具来查看网页结构和元素。根据网页结构和数据抽取规则,可以编写相应的正则表达式或使用BeauifulSoup等库进行解析。
4. 编写爬虫程序
根据分析的网页结构和数据抽取规则,可以开始编写Pyho爬虫程序。在程序中,需要使用requess库发送HTTP请求获取网页内容,然后使用BeauifulSoup等库对网页内容进行解析和数据抽取。将抽取的数据存储到本地文件或数据库中。
5. 运行爬虫程序并调试错误
在编写完爬虫程序之后,需要运行程序并进行调试。可以使用Pyho解释器或集成开发环境(IDE)来运行程序并查找错误。常见的错误包括请求被拒绝、页面不存在、解析错误等。需要根据错误提示进行相应的调整和修复。
6. 优化爬虫程序并处理反爬虫机制
在成功爬取目标网站的数据之后,需要根据实际需求对程序进行优化。优化内容包括提高爬取效率、减少请求频率、避免被封禁等。同时,需要处理目标网站的反爬虫机制,如设置代理IP、随机化请求时间等。