Python爬虫是一种使用Python语言编写的自动化程序,用于从互联网上获取数据。这些数据通常是从网页上抓取的,然后存储在本地计算机或数据库中进行分析和处理。
Python爬虫的原理是使用HTTP协议向目标网站发送请求,获取网页的HTML代码,然后通过解析HTML代码获取所需的数据。一般来说,Python爬虫需要使用到一些第三方库,如requests、BeautifulSoup、Scrapy等。
在Python爬虫的编写过程中,需要注意以下几点:
1. 遵守网站的爬虫协议,尊重网站的数据隐私和版权。
2. 不要频繁地访问目标网站,避免对网站服务器造成过大的负载。
3. 对于大规模的数据抓取,需要分批次、有计划地进行,避免被封禁。
4. 对于复杂的网页结构,需要使用适当的解析工具和技术,确保数据的准确性和完整性。
在Python爬虫的应用方面,可以用于以下场景:
1. 数据分析和挖掘:通过爬取大量的数据,进行数据清洗、分析和挖掘,发现数据背后的规律和趋势。
2. 竞品分析:通过爬取竞争对手的网站数据,了解竞争对手的产品、价格、销售情况等信息,为企业的决策提供参考。
3. 价格监测:通过爬取商品的价格信息,监测价格波动情况,为企业制定合理的价格策略提供依据。
4. 舆情分析:通过爬取互联网上的新闻、评论等信息,了解公众对企业的态度和反馈,为企业的公关和营销提供参考。
Pyho爬虫揭秘:如何高效地获取海量数据
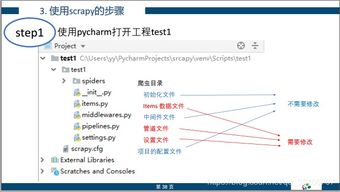
随着互联网的快速发展,数据已经成为企业竞争的核心资源。如何获取海量数据并进行分析,成为了很多企业和个人关注的焦点。而Pyho爬虫技术,正是实现这一目标的重要手段之一。
一、Pyho爬虫概述

Pyho爬虫是指使用Pyho语言编写的自动化程序,用于从指定的网站或数据源中获取所需的数据。通过Pyho爬虫,我们可以快速地获取大量数据,提高工作效率,降低成本。
二、Pyho爬虫实现原理
Pyho爬虫的实现原理主要包括两个方面:一是模拟人的浏览器行为,二是解析网页内容。
1. 模拟人的浏览器行为
Pyho爬虫需要模拟人的浏览器行为,以便能够正常地访问目标网站。这主要包括发送HTTP请求、接收HTTP响应、解析HTML页面等。在这个过程中,需要使用到一些第三方库,如requess、BeauifulSoup等。
2. 解析网页内容
解析网页内容是Pyho爬虫的核心技术之一。我们可以通过一些第三方库,如BeauifulSoup、lxml等来解析HTML页面,获取所需的数据。在解析网页内容时,需要注意一些反爬虫机制的应对方法,如设置合理的爬取频率、避免被目标网站封禁等。
三、Pyho爬虫应用场景

Pyho爬虫的应用场景非常广泛,如电商、金融、教育等各个行业。例如,电商行业可以通过爬虫技术获取竞品的价格、促销信息等;金融行业可以通过爬虫技术获取股票、基金等金融产品的数据;教育行业可以通过爬虫技术获取在线课程、题库等资源。
四、Pyho爬虫注意事项

2. 合理设置爬取频率
在爬取数据时,需要合理设置爬取频率,避免对目标网站造成过大的负载压力。同时,也要避免被目标网站封禁,影响正常的爬取工作。
3. 注意数据清洗和去重
在获取数据后,需要进行数据清洗和去重处理,以便得到更加准确的分析结果。同时,也要注意保护数据的隐私和安全。