1. 请求网页数据
```python
import requests
url = 'http://example.com'
response = requests.get(url)
data = response.text
```
2. 使用BeautifulSoup解析HTML
```python
from bs4 import BeautifulSoup
soup = BeautifulSoup(data, 'html.parser')
title = soup.title.string
```
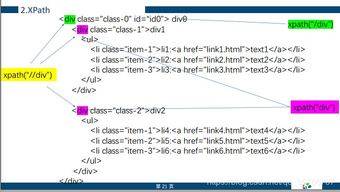
3. 使用XPath定位元素
```python
from lxml import etree
tree = etree.HTML(data)
title = tree.xpath('//title/text()')[0]
```
4. 模拟登录表单提交
```python
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlencode, quote_plus
url = 'http://example.com/login'
data = {'username': 'myusername', 'password': 'mypassword'}
response = requests.post(url, data=data)
soup = BeautifulSoup(response.text, 'html.parser')
```
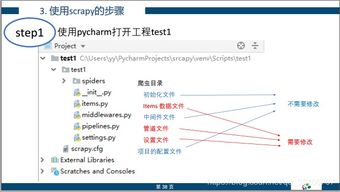
5. 使用Scrapy框架进行爬虫操作
创建一个Scrapy项目:scrapy startproject myproject。在项目目录下创建一个Spider类:scrapy genspider myspider example.com。然后在Spider类中编写爬虫代码。例如:
```python
import scrapy
from scrapy.selector import Selector
from myproject.spiders import MySpider
from myproject.items import MyItem
class MySpider(MySpider):
name = 'myspider'
start_urls = ['http://example.com']
def parse(self, response):
selector = Selector(response)
item = MyItem()
item['title'] = selector.xpath('//title/text()')[0].extract()
return item
```
爬虫Pyho代码大全
一、爬虫基础知识
网络爬虫是自动从网站抓取信息的程序。在Pyho中,最常用的爬虫框架是BeauifulSoup和Scrapy。BeauifulSoup用于解析HTML或XML文件,Scrapy是一个更强大的爬虫框架,可以用来构建复杂的爬虫项目。
二、爬虫库介绍
1. BeauifulSoup:用于解析HTML和XML文件的库。它提供了简单易用的API,可以方便地提取标签、属性、文本等数据。
2. Scrapy:一个用于爬取网站的框架,可以方便地构建复杂的爬虫项目。它提供了许多功能,如自动跟踪链接、提取数据、存储数据等。
3. Requess:一个用于发送HTTP请求的库,可以方便地获取网页内容。
4. lxml:一个用于解析HTML和XML文件的库,比BeauifulSoup更快更强大。
5. seleium:一个用于模拟浏览器行为的库,可以用来爬取动态加载的网页内容。
三、爬虫实战案例

1. 爬取豆瓣电影Top250列表:通过使用BeauifulSoup库,我们可以轻松地爬取豆瓣电影Top250列表并提取数据。
2. 爬取京东商品信息:通过使用Scrapy框架,我们可以构建一个复杂的爬虫项目来爬取京东商品信息。
4. 爬取微信公众号通过使用seleium库和BeauifulSoup库,我们可以模拟浏览器行为来爬取微信公众号文章内容。
四、爬虫反爬技巧
1. 避免被检测出是爬虫:通过设置请求头、代理IP、延时请求等方式来避免被检测出是爬虫程序。
2. 加密数据和防止IP被封:可以使用加密算法对数据进行加密处理,同时可以通过设置代理IP和限制请求频率来防止IP被封。
3. 使用User Age欺骗:伪装成正常浏览器用户访问网站,可以通过随机生成User Age来实现。
4. Cookie处理:对于需要登录才能访问的网站,需要处理Cookie,可以通过模拟登录过程获取Cookie信息。
6. 使用Web服务API:如果网站提供了Web服务API,可以通过调用API来获取数据,而不是直接爬取网页内容。
7. 限制爬虫速度:通过限制爬虫的请求频率和并发请求数量来避免对目标网站造成过大压力。
8. 使用分布式爬虫:将爬虫程序分布到多台服务器上运行,以分散对目标网站的访问压力。
9. 使用WebScraper插件:WebScraper是一个Chrome插件,可以在浏览器中直接查看网页结构,方便调试和开发爬虫程序。
10. 尊重网站的使用条款:在编写爬虫程序之前,一定要仔细阅读目标网站的使用条款,尊重网站的规则和政策。